개념

로드 밸런서 (Switch/LB)
- 이름 그대로, 사용자의 요청을 서버에 분배하는 역할을 한다.
- 서버에 가해지는 트래픽을 여러 대의 서버에 고르고 분배하서, 특정 서버의 부하를 막아준다.
짚고 넘어갈것
💡DNS에서 알려주는 IP주소는 최종 목적지 서버의 IP 주소야? 아니면 로드밸런서의 IP 주소야?
🗣️ 일반적인 대규모 서비스에서는 로드밸런서의 IP 주소를 가리키고 있다.
⇒ 이후 로드밸런서가 적합한 최종 목적지 서버로 요청을 전달한다.
로드밸런싱의 이점
로드 밸런싱은 여러 서버나 컴퓨터 자원에 작업을 고르게 분산하는 기술이다.
로드밸런싱으로 인해 아래와 같은 이점을 얻을 수 있다.
- 가용성
- 로드 밸런서는 서버 문제를 자동으로 감지하고 클라이언트 트래픽을 사용 가능한 서버로 리다이렉션하여 시스템의 내결함성을 높인다.
- Ex) 애플리케이션 가동 중지 없이 애플리케이션 서버 유지 관리 또는 업그레이드 실행
- 확장성
- 로드 밸런서를 사용하여 여러 서버 간에 네트워크 트래픽을 지능적으로 전달할 수 있습니다.
- Ex) 필요한 경우 다른 서버를 추가하거나 제거할 수 있도록 애플리케이션 트래픽을 예측합니다.
- 보안
- 로드 밸런서에는 인터넷 애플리케이션에 또 다른 보안 계층을 추가할 수 있는 보안 기능이 내장되어 있습니다.
- Ex) 공격 트래픽을 여러 백엔드 서버로 자동으로 리다이렉션하여 영향 최소화
- 성능
- 로드 밸런서는 응답 시간을 늘리고 네트워크 지연 시간을 줄여 애플리케이션 성능을 향상시킵니다.
- Ex) 클라이언트 요청을 지리적으로 더 가까운 서버로 리다이렉션하여 지연 시간 단축
로드밸런싱 알고리즘
- Roud Robin(순차) : 사용자 요청을 서버에 순차적으로 하나씩 분배
- Least Connection(최소 접속방식) : 열려있는 커넥션이 가장 적은 서버로 사용자 요청을 분배, 트래픽을 나누기 전에 서버의 현재 상태를 검사해야하는 동적 로드밸런싱이다.
- 가중치 기반 : 서버 성능에 따라 트래픽을 다르게 분배
- IP 해시 방식 : 특정 클라이언트는 항상 정해진 서버로 연결되도록 설정
일반적으로 많이 알고 있는 알고리즘들은 각각의 장단점이 있다. 그렇기 때문에 서버 성능과 요청/트래픽 등을 고려하여 적절한 알고리즘을 선택하는 것이 중요하다.
Roud Robin, Least Connection 둘의 성능은 생각보다 차이가 나지 않는다고 한다.
⇒ 그렇다면 사용자의 요청을 기반으로 로드밸런싱을 할수도 있지 않을까
- L2(MAC address) / L3(IP address) 는 기능이 제한적이라 사용을 잘 안한다.
- L4(TCP 관련) / L7(Application 관련) 을 실제로 많이 사용한다.
L4 vs L7
- L4
- [단지 부하 분산용] IP, Port 기준으로 스케줄링 알고리즘을 통해 부하를 분산
- RR/Health Check 등의 기능을 모두 지원하며, L7보다 빠르다.
- 빠른 이유는 다른 계층의 정보들을 고려하지 않아도 되기 때문이다.
- L7
- [콘텐츠 기반 스위칭] IP, Port 외에도 URI payload HTTP header, cookie등의 내용을 기반으로 부하를 분산
- 더 다양한 기능을 가지고 있다.
- HTTP 헤더/쿠키 등의 정보를 활용하거나, 패킷의 내용을 확인하고 그 내용을 기반으로 서버에 분배한다.
SPOF(Single Point Of Failure)
SPOF : 시스템이나 프로세스에서 장애가 발생할 수 있는 단일 장애 지점
그렇다면 만약 로드밸런서가 망가지게 되면 모든 시스템이 중단될 수 있다.
1. DNS Round Robin
- DNS를 사용해서 도메인 정보를 조회하는 시점에 다른 IP를 줘서, 트래픽을 분산하는 방법
- 언제 쓰는가?
- 지리적으로 복수의 웹 서버가 멀리 떨어져 있어서 실시간으로 헬스 체크가 어려울 때 사용한다. (혹은 적은 비용으로 구현이 필요할때)
- (주의점) Healtch Check에 대한 대안이 없다.
- 해당 IP의 로드밸런서가 정상이라는 전제를 만족하지 못함
- 가용성이 필요한 경우에는 health check 기능이 포함된 DNS 서비스인 AWS Route53을 쓰는것도 좋은 예다.
- (주의점) 사용자 환경이나 ISP DNS에 IP가 Caching 되어 있을 수 있다.
- DNS 캐시가 있다면 원하는 대로 DNS 로드 밸런싱이 안될 수 있다.
- 따라서 로드밸런싱의 용도로 사용시 A 레코드의 캐싱 주기를 가급적 짧게 설정해야한다.
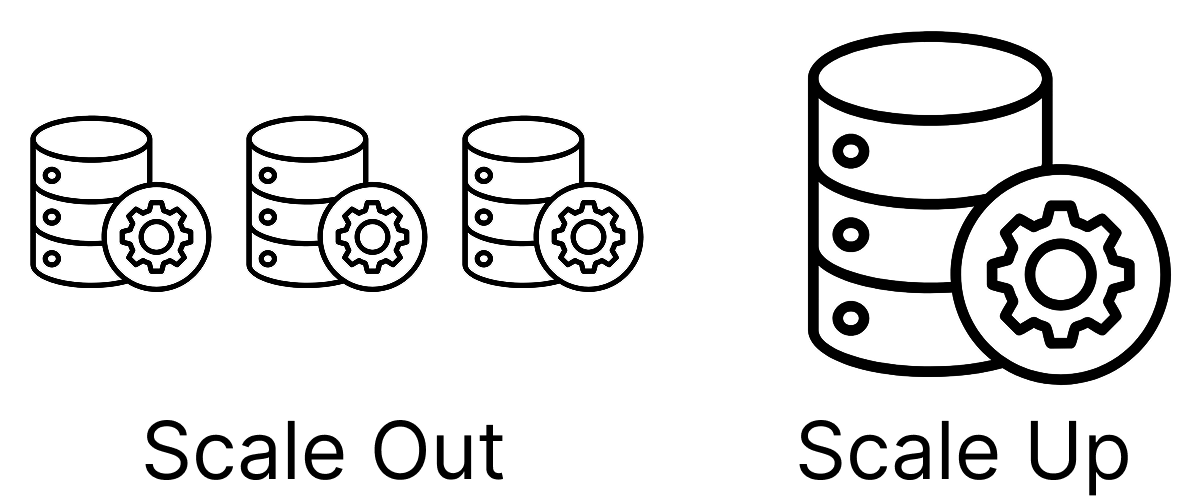
2. SPOF Scale Out
Scale Out이 가능하다면 그냥 서버의 개수를 늘리고, 해당 서버/로드밸런서가 죽어 있다면 안보내면 된다.
Health Check
그렇다면 해당 로드밸런서나 서버가 죽었다는 것을 어떻게 알고 분배할까
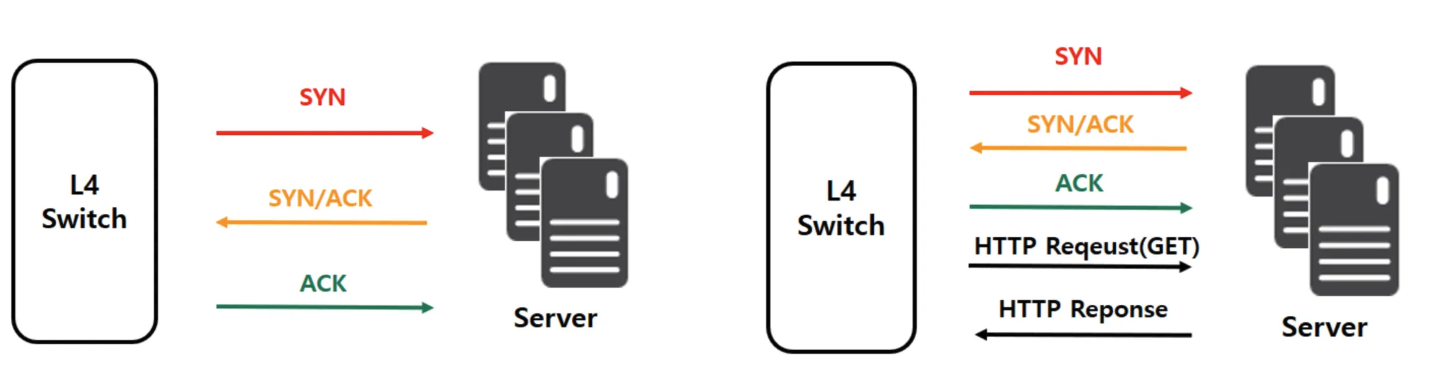
- TCP를 이용
- 3 way handshake를 통해 SYN, SYN ACK, ACK를 정상적으로 주고받으면 정상 판단
- [AWS Route 53] 10초 이내에 TCP 연결을 할 수 있어야지 정상으로 판단
- HTTP를 이용한 Health Check
- 3 way handshake와 HTTP의 상태코드까지 추가로 확인해야한다.
- [AWS Route 53] 4초 이내에 TCP 연결, 2초 이내에 HTTP 200 상태코드 응답 확인을 해야지 정상으로 판단
- 그외
- ICMP : ping으로 살아있는지 여부만 체크
- TCP Half Open : 3 Way handShake를 하고, 이후에는 ACK 대신 RST으로 세션 끊기
- L7, 콘텐츠 확인(문자열 확인) : 지정된 콘텐츠가 정상적으로 응답했는지 여부를 확인
- [AWS Route 53] 지정한 문자열을 찾기 위해 본문의 최초 5,120 바이트 내에서 나타나야한다.
[논외] NginX의 HTTP 로드밸런싱
NginX는 트래픽이 많은 웹사이트의 서버(WAS)를 도와주는 비동기 이벤트 기반구조의 경량화 웹 서버다.
- 클라이언트로부터 요청을 받았을 때 요청에 맞는 정적 파일을 응답해주는 HTTP Web Server로 활용되기도 하고
- Reverse Proxy Server로 활용하여 WAS의 부하를 줄일 수 있는 로드밸런서 역할을 하기도 한다.
리버스 프록시는 웹 서버 앞에 위치하여 클라이언트(예: 웹 브라우저) 요청을 해당 웹 서버에 전달한다.
1️⃣ 정방향 프록시는 클라이언트 앞에 위치하며 원본 서버가 해당 특정 클라이언트와 직접 통신하지 못하도록 하는 것
2️⃣ 리버스 프록시는 원본 서버 앞에 위치하며 어떤 클라이언트도 원본 서버와 직접 통신하지 못 하도록 한다.
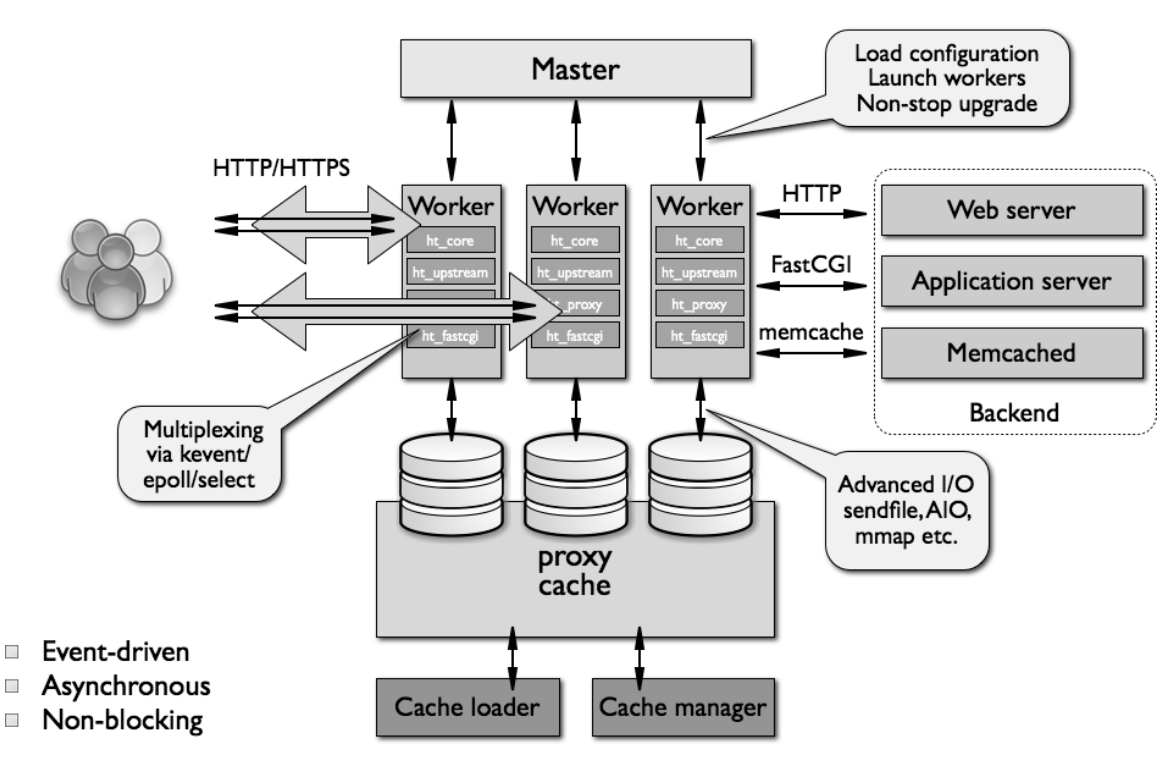
- Master Process : 구성 파일을 읽고 worker process유지 및 관리
- Worker Process : Single Thread로 구성되어 실제 사용자의 요청을 처리
- 제공하는 로드밸런싱 방법
- [기본 디폴트] Round Robin
http {
upstream myapp1 {
server srv1.example.com;
server srv2.example.com;
server srv3.example.com;
}
server {
listen 80;
location / {
proxy_pass http://myapp1;
}
}
}- Least Connection
upstream myapp1 {
least_conn;
server srv1.example.com;
server srv2.example.com;
server srv3.example.com;
}- IP hash
upstream myapp1 {
ip_hash;
server srv1.example.com;
server srv2.example.com;
server srv3.example.com;
}- Weighted
upstream myapp1 {
server srv1.example.com weight=3;
server srv2.example.com;
server srv3.example.com;
}
2. Health Check는 어떻게 하는가?
- 실패 횟수, 실패 타임아웃을 지정해서 헬스체크를 할 수 있다.
upstream myapp1 {
server srv1.example.com max_fails=3 fail_timeout=30s;
server srv2.example.com;
server srv3.example.com;
}
3. 추가적인 기능
- proxy_next_upstream : 실패한 요청을 다른 서버로 재전송
- backup : 특정 서버를 백업 서버로 지정
- 그외... 많음 ^_^
[논외] Health Check가 가능한 DNS LB인 AWS의 Route53
실제 Route53를 어떻게 사용했는지에 대한 AWS 고객사들의 케이스가 많이 소개되어있다.
그중에서도 Netflix는 Route53을 활용해서 애플리케이션 복원력을 어떻게 개선 했는가에 대한 유튜브 영상이 있어서 그 중 설계법에 대한 사진을 가져왔다.
아래의 경우에는 DNS 로드 밸런싱을 통해 트래픽을 분산하고, 도중 문제가 생긴 서버가 감지 되면 다른 IP로 나눌 수 있게끔 설계가 되어 있다.

아래의 경우에는 노션은 Route53을 사용해 API 보안 및 성능 개선에 대한 케이스 소개다.
위와 조금 다른 경우지만 그냥 이렇게 설계되어 있구나를 보고 싶어서 가져와봤다.
Reference
[로드밸런서 개념] https://www.smileshark.kr/post/what-is-a-load-balancer-a-comprehensive-guide-to-aws-load-balancer
[L4 Health Check] https://aws-hyoh.tistory.com/102
[넷플릭스 Route53] https://www.youtube.com/watch?v=WDDkLOT8SCk&list=PLhr1KZpdzukdeX8mQ2qO73bg6UKQHYsHb&index=14
[Notion Route53] https://aws.amazon.com/ko/solutions/case-studies/slack/?did=cr_card&trk=cr_card
[Route 53 Health Check 정책] https://docs.aws.amazon.com/ko_kr/Route53/latest/DeveloperGuide/dns-failover-determining-health-of-endpoints.html
[NginX LB] https://nginx.org/en/docs/http/load_balancing.html
'Programming > CS' 카테고리의 다른 글
| @Transactional 도대체 언제 쓰고 언제 안써야해? (0) | 2025.02.26 |
|---|---|
| [운영체제] ThreadPool /Blocking Queue의 종류들은 각각 언제 사용할까 (1) | 2025.02.04 |
| [DB] 데이터베이스와 SQL (0) | 2022.09.19 |
| 6장 프로세스 (0) | 2020.12.30 |
| 5장 쉘과 명령어 사용 (0) | 2020.12.30 |



댓글